If you found value in this post, consider following me on X @davidpuplava for more valuable information about Game Dev, OrchardCore, C#/.NET and other topics.
Basics - Continued
This is Part 2 of a multi-part review of Microsoft's Semantic Kernel SDK.
You can read Part 1 - Getting Started here.
Intro
In Part 1, we covered getting started with Microsoft's Semantic Kernel by working through the Polyglot Notebooks in the GitHub repository.
We covered tools used, contstructed a Kernel, creating prompts with arguments, and a simple chat bot example.
This part continues working through the Polyglot notebooks to cover planning, memory, embeddings and other features.
Planning
The concept of Planning in Semantic Kernel is interesting, and very cool.
If you recall from Part 1, a Kernel app composes together Kernel Plugins and Kernel Functions to achieve a desired outcome.
But how do these Plugins and Functions work together to solve the problem?
Planning.
Semantic Kernel uses a concept called Planning to decide when, how and with what arguments to call a Kernel's plugins and function.
More accurately, Semantic Kernel uses AI itself, a LLM to draft a plan to achieve that goal. This plan is a series of plugin/function calls to get to the final result.
Old vs. New
Interestingly, at the time of this writing, Semantic Kernel recommends that you use a feature of LLMs called "function calling" to create a plan for a user using your AI agent.
The "old" way was to use built in types for "Stepwise" and "Handlebar" planners is superseded in favor of using LLMs that support "function calling".
Note, that "function calling" requires your Chat Completion service to use an LLM that supports it.
Planning Example
Note, this Polyglot Notebook uses the "old" way with a Handerbars planner.
The subsequent Notebook in the Semantic Kernel repository makes use of the SummarizePlugin and WriterPlugin which are parameterized prompt templates.
The SummarizePlugin has function prompts for making abstracts readable, note generation, summarization, and topics.
The WriterPlugin has prompt functions for several things such as email, acronyms, novels, stories and poems.
As before, a basic Kernel app is constructed with an OpenAI chat completion service.
The next steps, rationally, are to configure the the Summarize and Writer Plugins within the Semantic Kernel.
Lastly, you can use the planner object, passing in your configured Kernel along with your request to get a plan of execution.
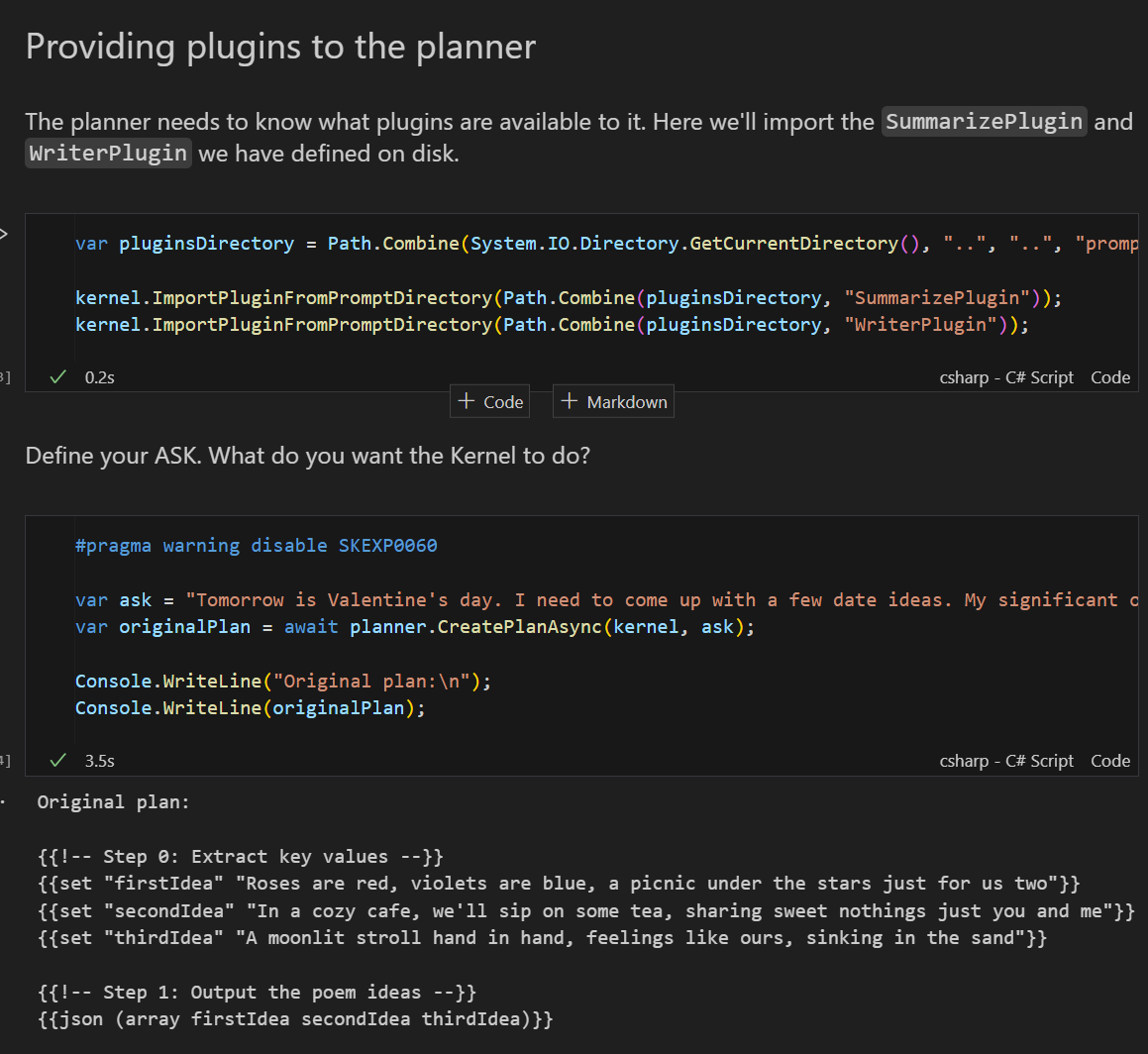
For this example, you are asking your Kernel to genereate multiple date ideas communicated using a poem.
As you can see, there are two steps to the plan.
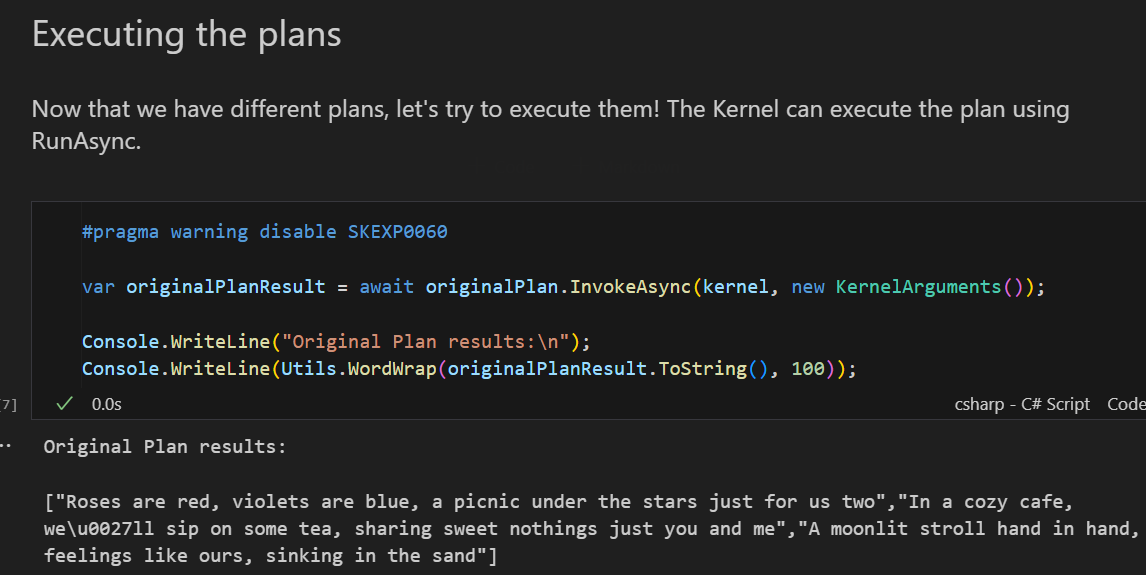
The final step is to execute the generated plan using the object returned by Semantic Kernel's planning step. This gives you the desired output.
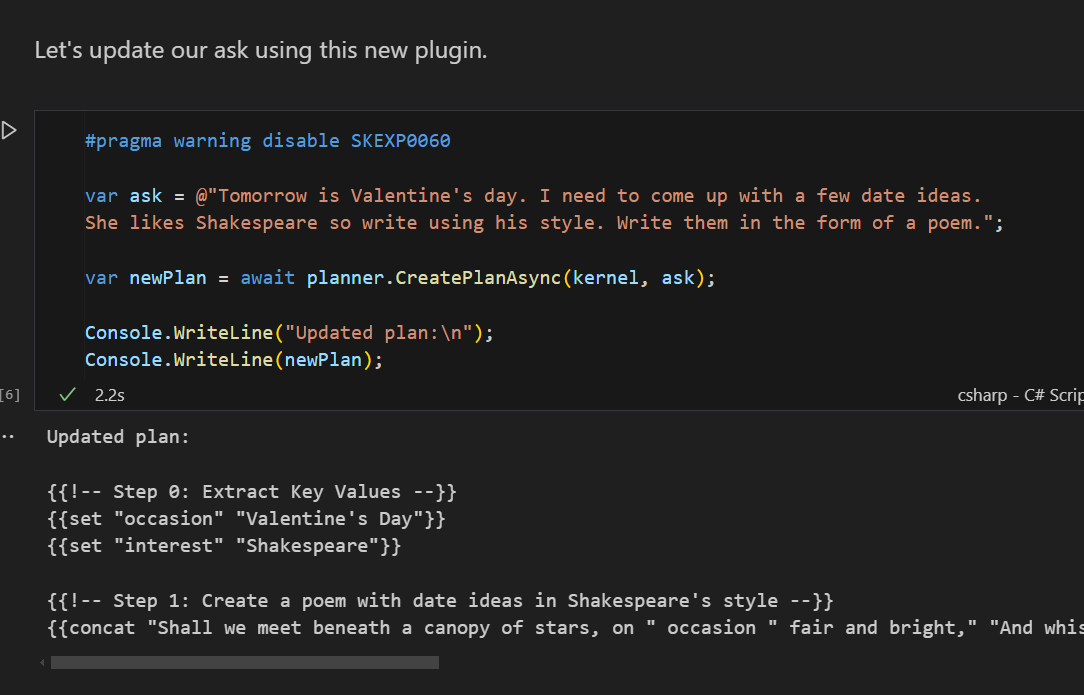
As a little twist, the Notebook has you add an inline function to rewrite output in a Shakespearean style.
Which you can add to your Kernel app, and then write write the date idea peoms in the style of Shakespeare.
Analyzing the Example
So what's going on here?
Looking more closely at the defined prompt of the Rewrite function in the Writer plugin, you see inputs for $style and the actual $input of the user request.
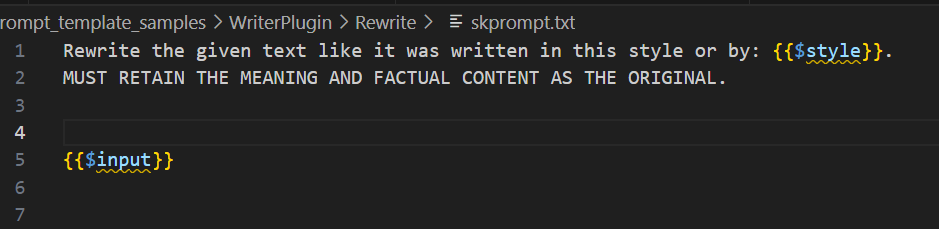
The planner uses the context given by the user describing how it is Valentine's Day and that you what date ideas written as a poem. It then is able to use the LLM to determine which values to extract from the user's request context, and configure that as the input Kernel Arguments for the Rewrite function in the Writer plugin.
You're essentially using the LLM to figure how to better prompt the LLM. Which is very cool.
Memory
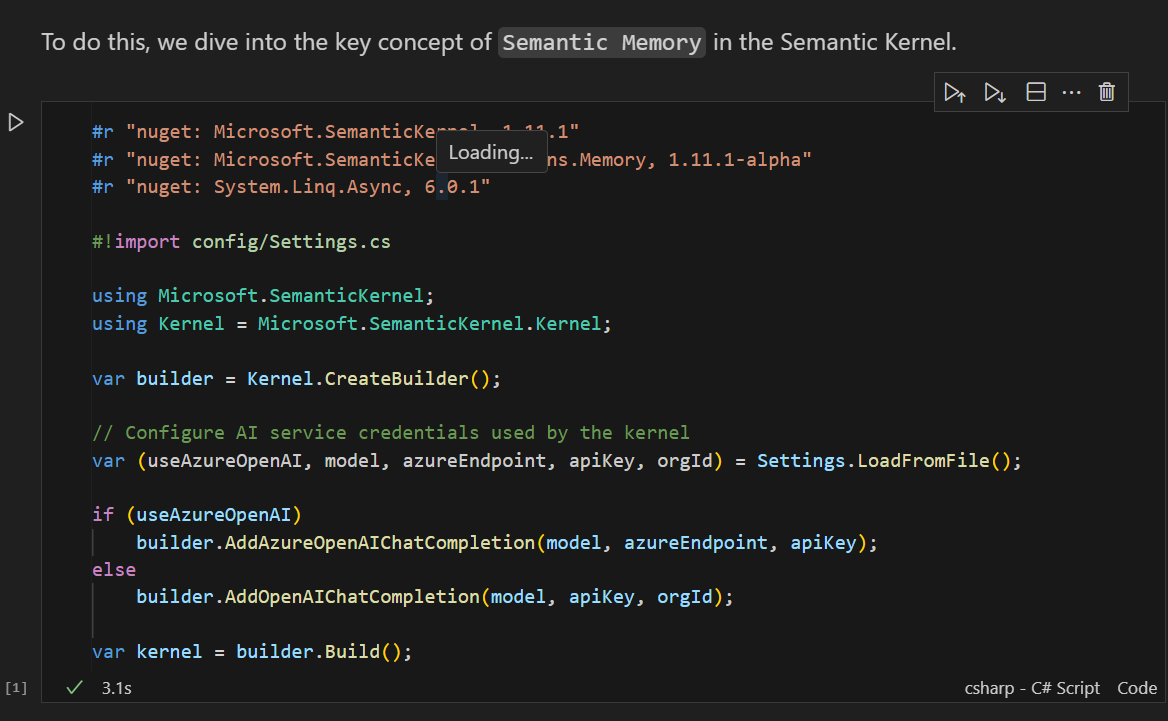
Moving on to the next Juputer Notebook in Semantic Kernel's GitHub repository, we get to Semantic Memory, which is a way to persist state within your Kernel application for more interesting applications.
The start of the notebook is the familiar builder pattern setup for a Kernel application.
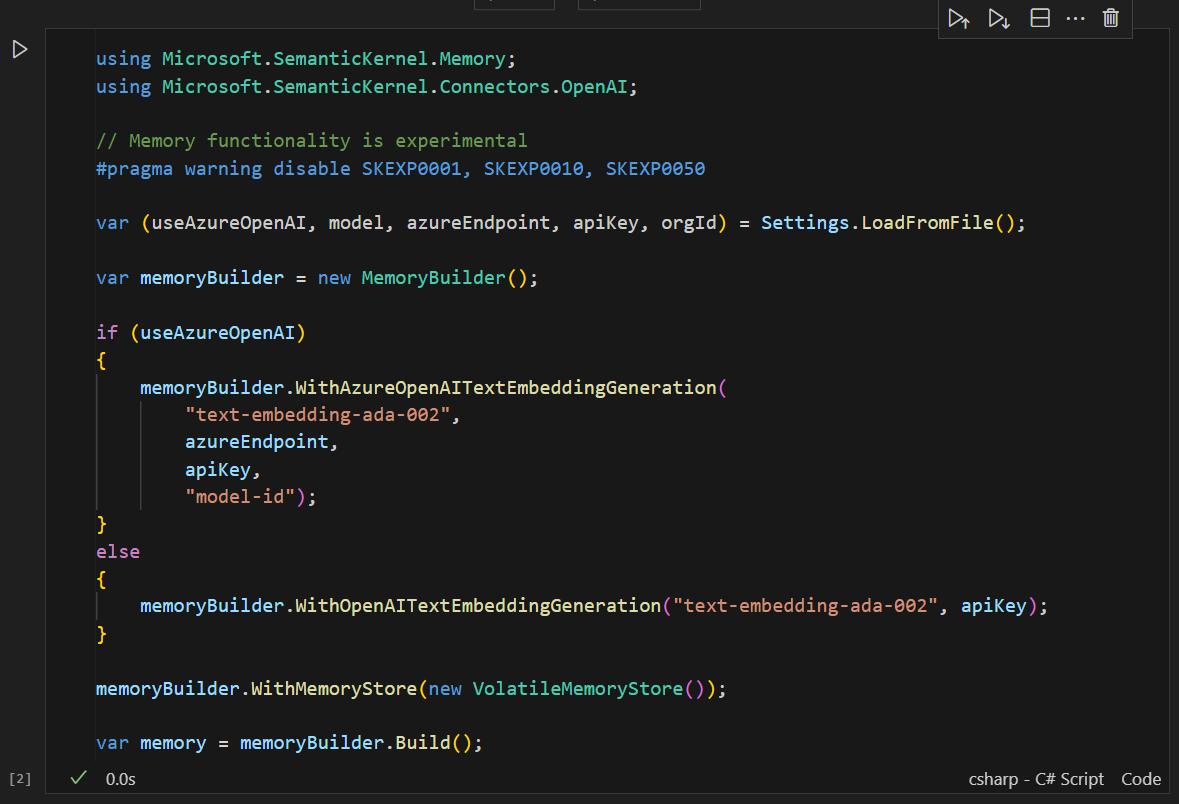
Conceptually, a Kernel plugin for Memory is used, but also a Memory storage technology.
The Polyglot notebook uses an in-memory solution called VolatileMemoryStorage which is NOT persistent across sessions but there are different storage implementations that give you persistence.
Embeddings
At the time of this writing, the Microsoft documentation for embeddings is limited. Looks like they are in the process of adding it.
I'll update this section in the future.
Memory as a Data Structure
The starting point is to manually add some contrived examples of embdedding information about a person.
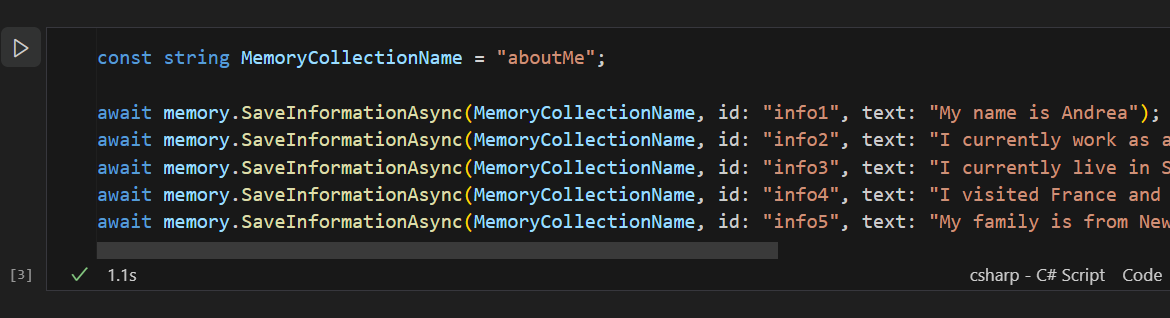
In short, generating emdeddings is all about turning your information into a set of floating point numbers that correspond to relevenace and meaning.
Here you see the about of turning those memories into vector embeddings.
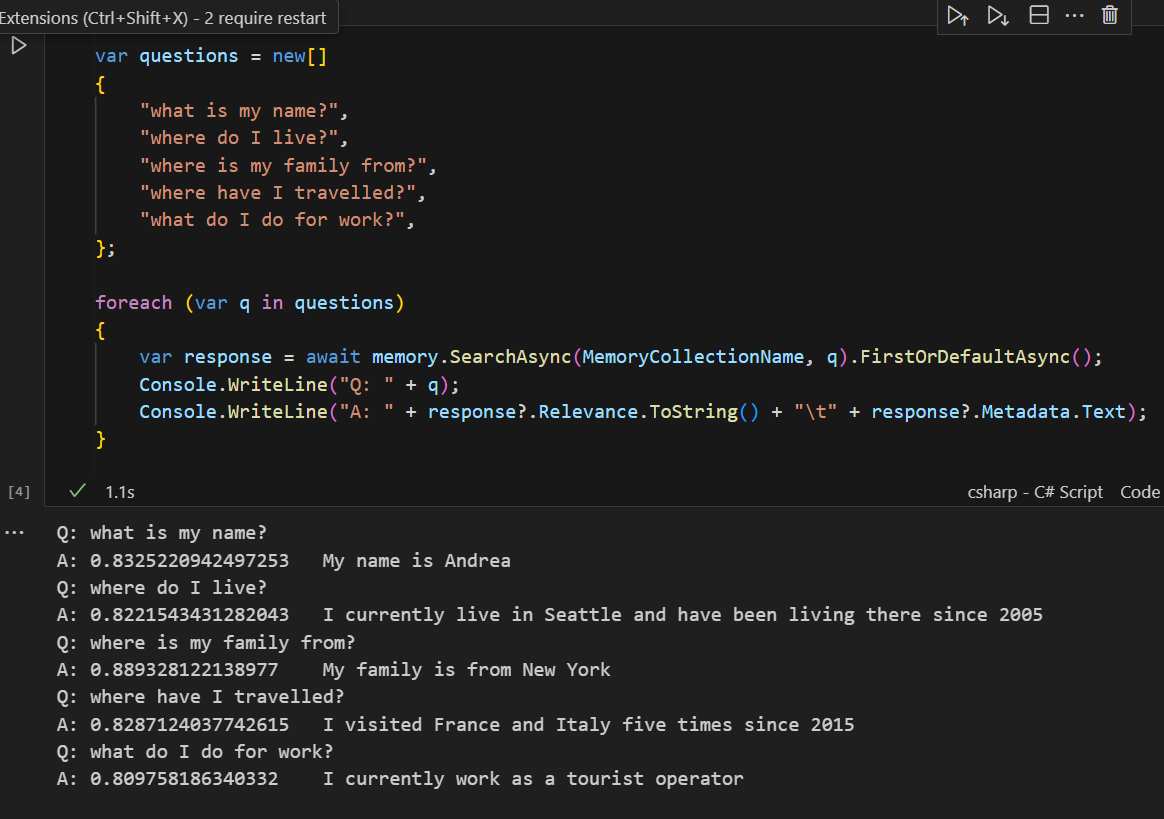
It's important to note that an OpenAI model for generating embeddings was used. You can see it was configured during initialization of the memory object.
Total Recall
It's nice that the tutorial refers back to the chat bot notebook from Part 1 so you can see how memory builds on top of prior work.
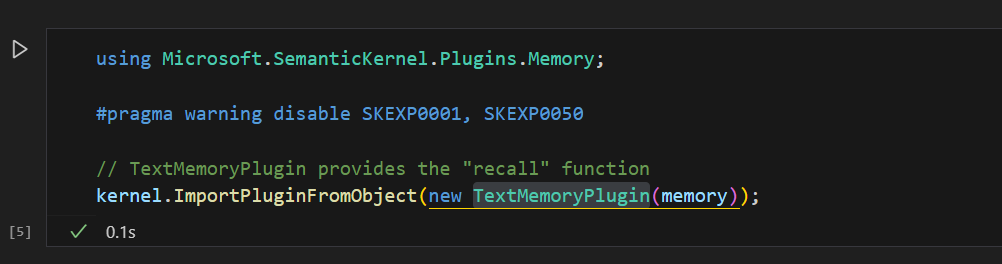
Semantic Kernal has a native TextMemoryPlugin with a recall function that returns the most relevant memory currently found in the storage medium backing Semantic Memory.
Add that to your Kernel app by importing it as an object.
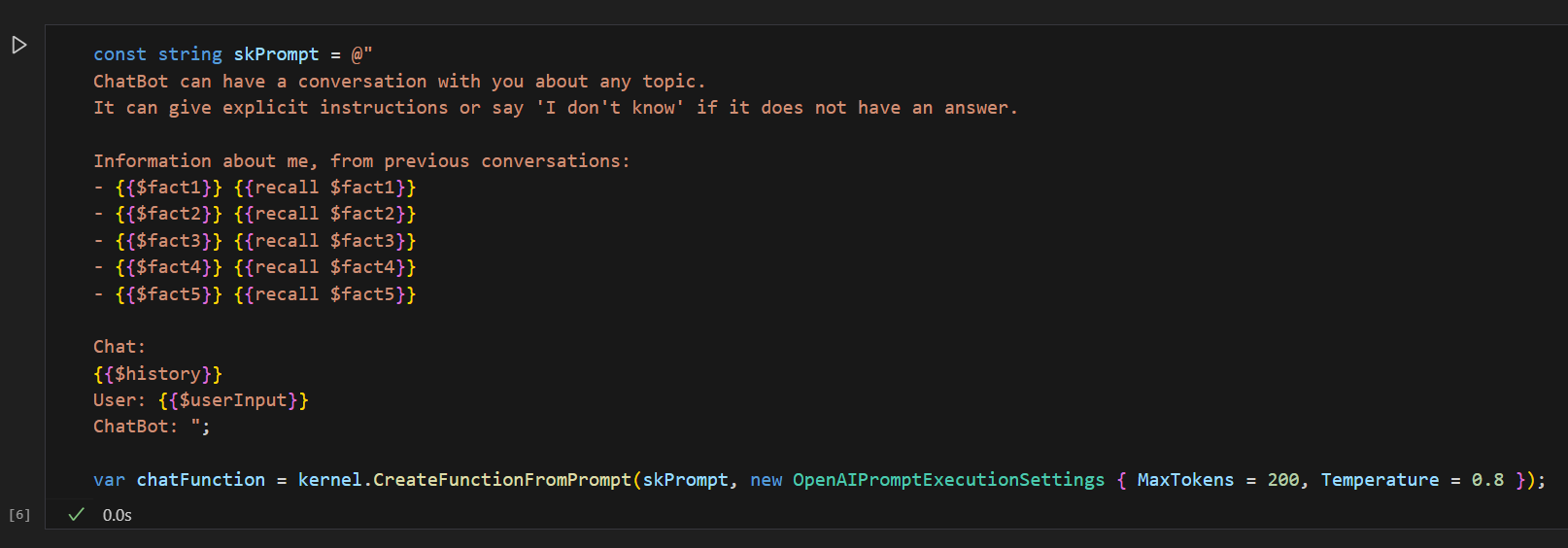
Now you can recreate the chat function that loops through your converstaion storing history, but using a prompt that is primed with the contrived information about yourself.
As always, be sure to set your Kernel Arguments to pass in.
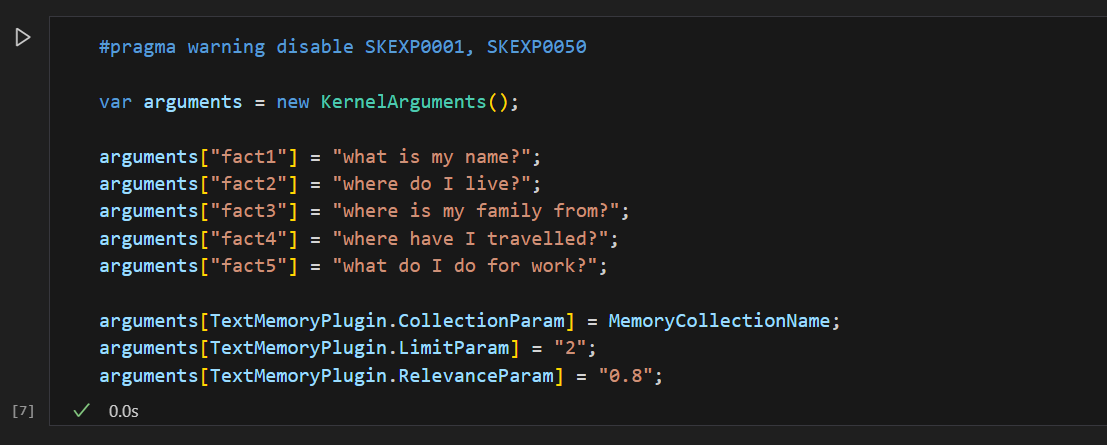
Essentially, you now have a chat bot that has information about you, so you can ask it context senstive questions about yourself.
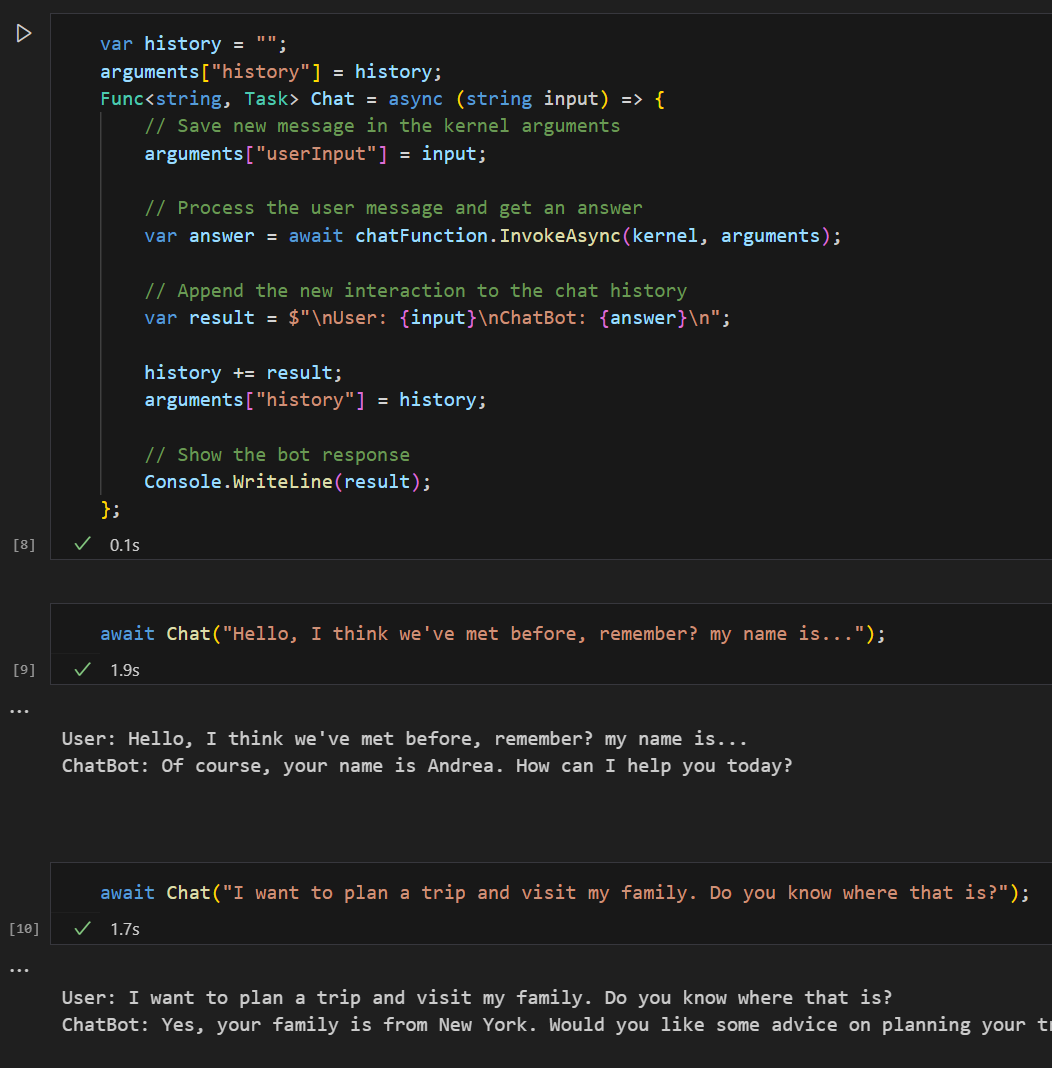
This demonstrates how you can use Semantic Memory, which is part of Semantic Kernel, as a way to inject context specific information.
Using this context like a user's personal information can provide a more personalized chat experience.
But this information is just contrived sample information, what is special about that?
Not much, but you can extend this concept to your own documents to get a better experience interacting with your data.
Talk to Me Goose
Have you ever wanted to chat with your data?
I have. And I think you will too.
Semantic Kernel provides a way to create embeddings of your own documents which you can then use within your Kernel app.
The notebook first has you build memories using files from the GitHub repository.
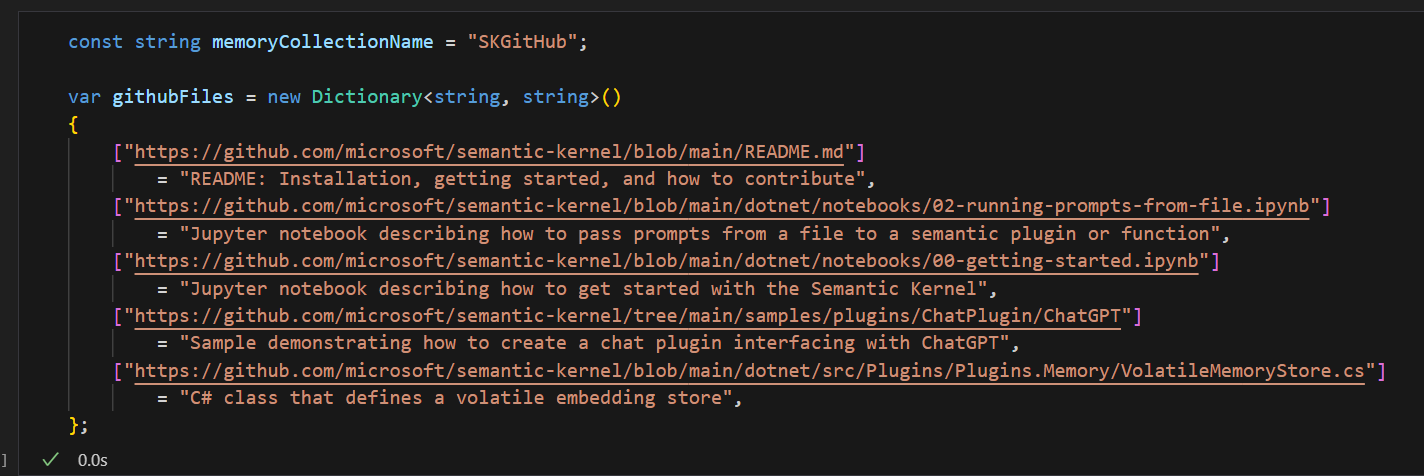
As before, you construct a memory builder object using the VolatileMemoryStore as the storage medium. You can see an example of that above.
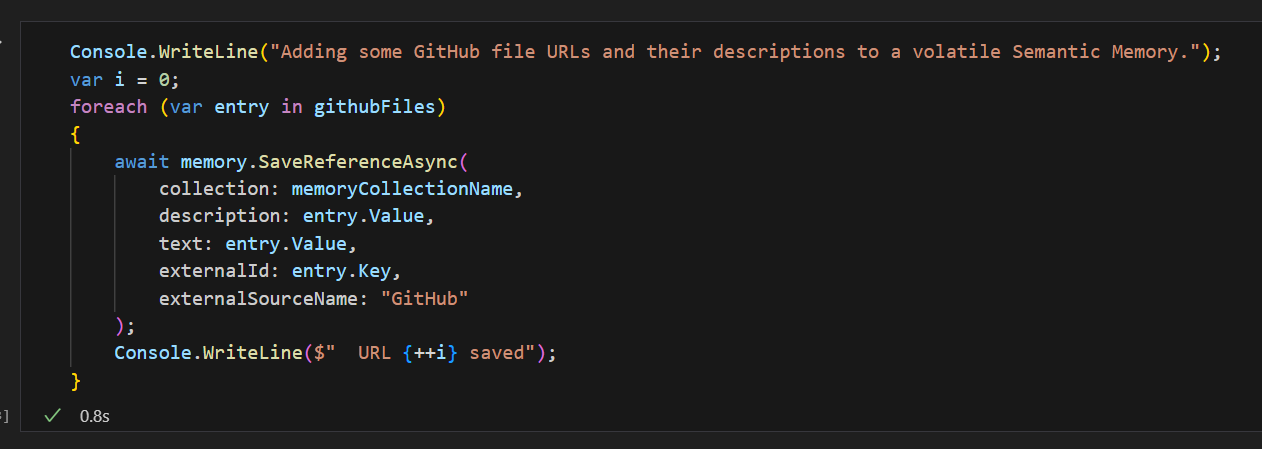
Iterating over the array of URLs, you add them to your memory data structure.
Now you can search the memory construct for your documents and elicit information about it using natural languange.
In the notebooks example, you can get a list of Polyglot notebooks by saying how much you like them when asking how to get started.
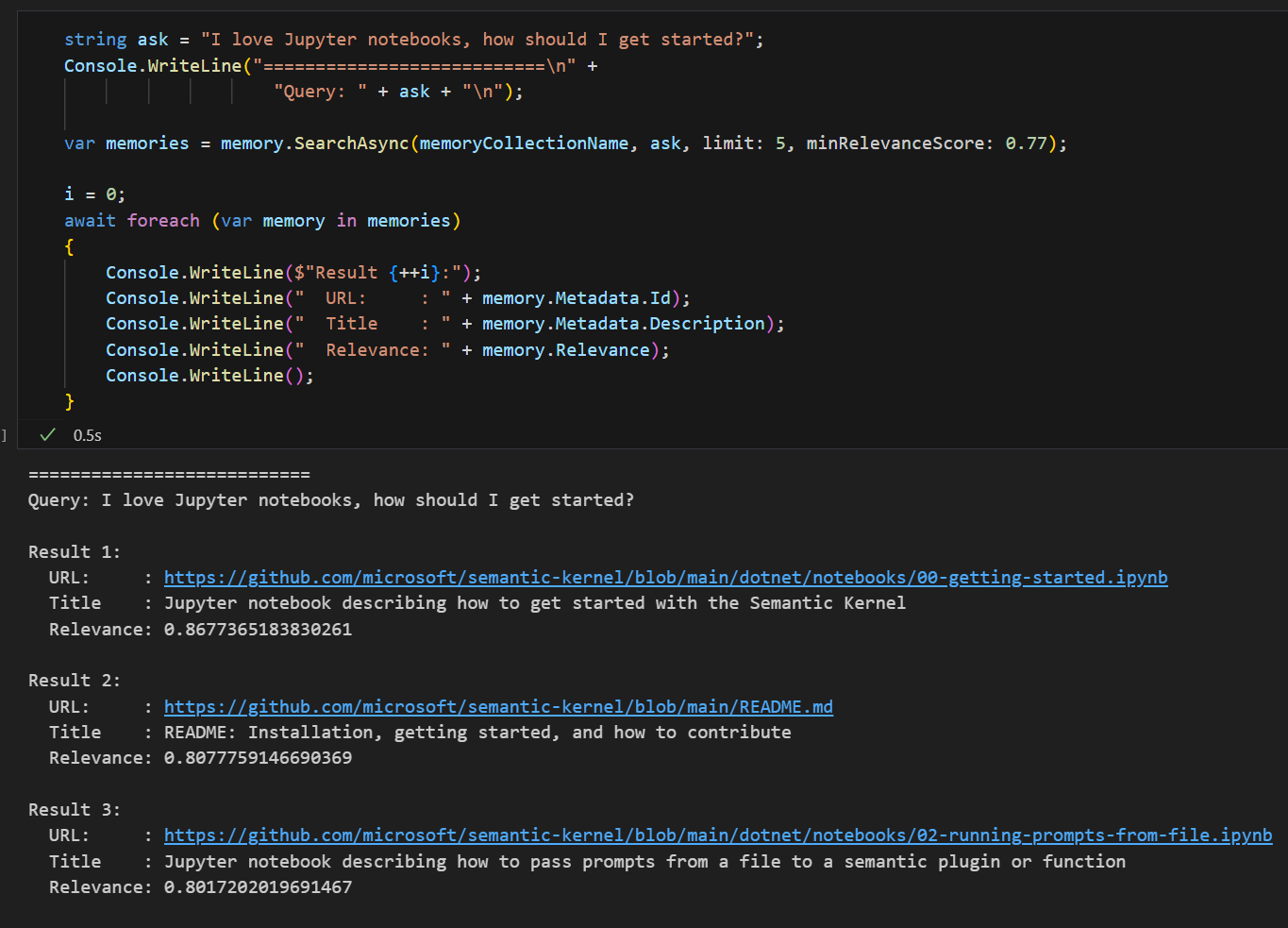
It's cool to imagine create a chat bot or other AI agent that can engage with your own data.
Conclusion
Getting deeper into the Semantic Kernel SDK, planning, memory and embeddings provide an enriching element to the art of design an AI agent.
Looking ahead to future parts, it looks like there are additional integrations with other AI services such as OpenAI's DALLE image generation service.
For details on getting started, see Part 1 of this series.